
本
文
摘
要
本文是网易云音乐机器学习平台与框架组刘长伟负责撰写,记录了云音乐机器学习平台与框架组在过去一年中,在图神经网络的相关工作
项目背景
随着从传统音乐工具软件到音乐内容社区的转变,云音乐依托音乐主站业务,衍生大量创新业务,如直播、播客、K歌等。创新业务既是机遇也为推荐算法同学带来了挑战:用户在创新业务中的行为稀疏,冷启动现象明显;即使是老业务也面临着如下问题:
如何为新用户有效分发内容将新内容有效分发给用户我们基于飞桨图学习框架 PGL,使用全站的用户行为数据构建用户的隐向量表征,刻画用户之间的隐性关系,提供个性化召回、相似挖掘、lookalike 等功能;
在实践中,我们遇到了各种难点挑战:
存在多种行为对象、行为类型;增加构图的复杂度;用户行为数据量大,近五亿节点(包含用户、歌曲、mlog、播客等),数百亿条边的数据规模;模型训练难,模型本身参数量巨大,需要大量系统资源;图计算模型迭代速度快,需要能够在大规模场景下支持模型快速开发;在企业界,落地像图神经网络这类技术时,需要着重考虑到成本的因素,成本主要包括两个方面:架构改造与计算资源;为解决这些难点,我们基于网易云音乐Goblin平台落地了以下具体的技术方案;
落地飞桨PGL GraphService 通用构图方案, GraphService 提供类似于图数据库,提供基于采样的服务;构图方案除了提供采样服务,还包括如何图数据如何存储,数据如何加载,如何满足不同模型的不同采样形式,以及这个服务是否可并行扩展,如何启动等一系列解决方案。后面会详细介绍;通过k8s MPI-Operator实现了超大规模图的构图及加载, MPI-Operator 提供并行计算任务,是实现通用构图方案可用易用必要的基础组件;整合k8s TF-Operator 与MPI-Operator解决模型分布式训练中的图存储与模型计算的问题;通过k8s virtual-kubelet 、cephfs实现计算存储资源弹性扩容,训练过程会消耗大量计算存储资源,训练结束,这些资源就会闲置,我们通过cephfs实现存储资源动态扩缩容;通过virtual-kubelet 将严选传媒等闲置计算资源引入Goblin机器学习平台,实现弹性扩容,按需计费;本文首先介绍一下Goblin平台,然后介绍实现超大规模图计算的技术栈,详细描述实践过程;最后简要讲解图计算模型的迭代;
网易云音乐goblin平台介绍
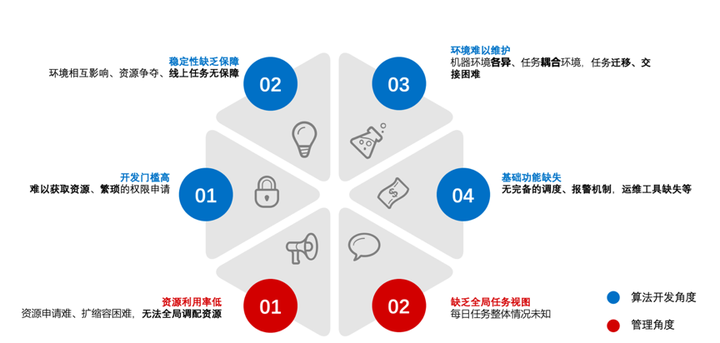
网易云音乐快速发展,机器学习应用场景越来越多,传统开发方式存在较多问题,下图从算法开发角度和管理员角度展示这些问题:
在数据平台团队与算法团队进行整合,成立数据智能部的大背景下,急需统一的基础设施来解决上述问题; 在参考阿里PAI、美团机器学习平台知乎;我们从0到1搭建并落地了基于k8s的容器化综合解决方案:

通过该平台为开发者提供:
标准的开发环境开发与线上环境统一简洁方便的运维工具集成的存储、端口、日志管理我们的超大规模图计算技术栈正是Goblin平台在并行计算任务、分布式训练任务的一个最佳实践;
超大规模图计算技术栈
图计算通过图来刻画实体之间的关系,云音乐场景产品业务多,用户行为复杂,数据量大,我们以一个典型场景为例:
在云音乐 APP 里,云音乐拥有大量的用户行为数据:
歌曲:点击、收藏、听歌等
歌单:点击、收藏等
播客:关注、点击等
直播:关注、点击、观看等
视频:点击、观看等
首先用户会对不同资源产生行为:点击歌曲,观看直播;其次相同用户和资源之间会有多种不同的行为:用户红心歌曲,用户点击歌曲;如下图所示:
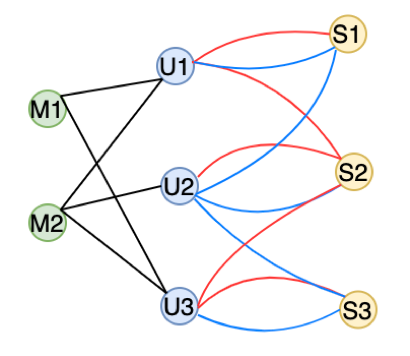
再看一下数据规模,以上用户和资源的关系图, 节点个数有 4.8 亿,而边数有 380 亿,这样的数据规模导致计算和推理复杂度非常高。
总结来说,云音乐图计算场景有高度异构、数据规模非常大的特点,这就要求:
通用的表达方案,不但能够表达简单的同构图、还能解决我们现在遇到的异构图、多连接图;能够高效存储、加载图数据通用的数据采样接口,支持不同模型在各种类型的图上的采样需求;能并行扩展:要能够横向扩展来应对超大规模的数据加载和采样;我们采用基于飞桨PGL GraphService的图切分方案配合Goblin平台提供的分布式计算、存储功能实现了满足以上要求的支持并行扩展超大规模图计算方案,本章将详细讲解该方案技术栈的每个细节;
3.1 图切分
以用户点击Mlog,红心歌曲,收藏歌曲为例;我们将完整的数据图切分为 ucm、uhs、ues子图,每个子图通过其资源和行为简写命名;
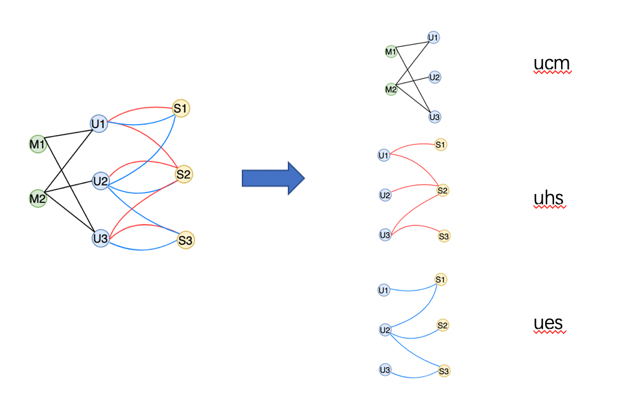
该方法优点:
可以将一个复杂的图切分为简单的异构图,化繁为简;除了表达上的简化,还简化了图数据的加载及模型采样流程;通用性,既能表达复杂的异构图,也能描述同构图、二部图等;3.2 GraphService
有了通用的表达方案,下一步就需要讨论图的加载、存储和采样方案了;我们采用基于飞桨PGL GraphService来实现;前面已经做过简述,这里将从服务编排、数据加载、采样流程来详细介绍;
GraphService任务编排:
GraphService由多个worker组成的分布式并行计算任务,Globlinlab平台上通过K8S MPI operator 实现任务一键编排:
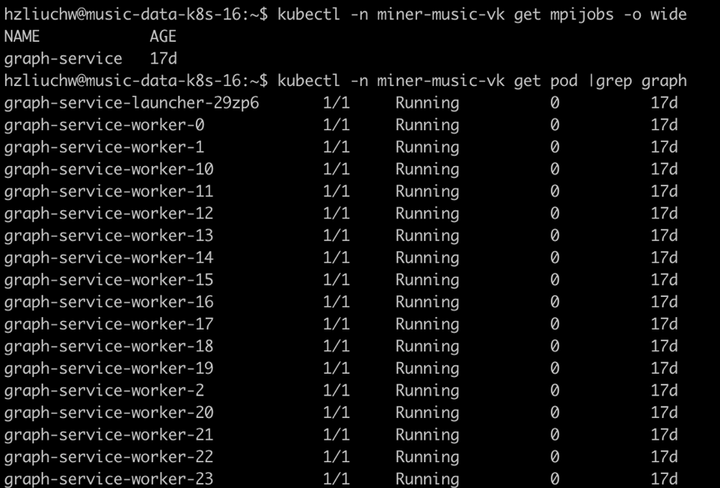
可以看到我们通过编排指令,启动了具有多个worker的GraphService服务;
数据加载:
GraphService启动后首先需要加载图数据,为了能够并行加载超大规模的数据,我们采用图数据shard,并行加载,具体步骤:
所有子图数据按 src 节点hash分到worker节点每个worker负责加载以所分得节点为起始节点的边每个worker加载所分得的节点featureWorker在加载完数据后,启动brpc服务,为client提供数据采样服务;GraphService在内部采用C++实现,存储效率非常高;
数据加载和采样都offload到worker端
采样:
训练任务通过GraphService的标准接口向GraphService服务端发起采样请求;目前提供的标准基础接口包括:
node_batch_iter:批量获取某个类型的节点
random_sample_nodes:随机获取某个类型的节点
sample_successor:获取参数节点的后继节点
get_node_feat:获取节点feature
我们在标准接口上,封装实现了metapath_randomwalk;通过配置metapath实现在不同子图上实现边的采样流程;
比如:metapath:uhs-shu , 采样流程如下图所示:
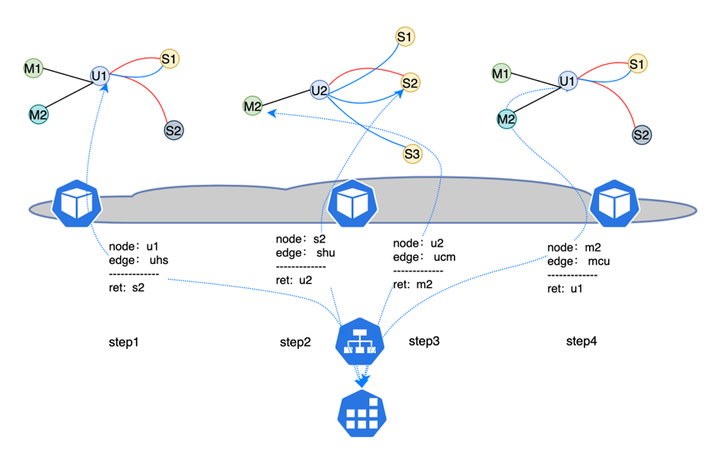
采样流程通过node_batch_iter接口从metapaht的起始类型节点中随机采样出节点u1 ; 通过metapath的知道,实现在uhs、ucm子图中的采样流程,最终得到样本序列:u1-s1-u2-m2-u1;
以上是得到的是随机游走的序列,也可以通过多个metapath,比如uhs 、ucm实现在u-s 、u-m类型的采样序列;
3.3 模型训练:
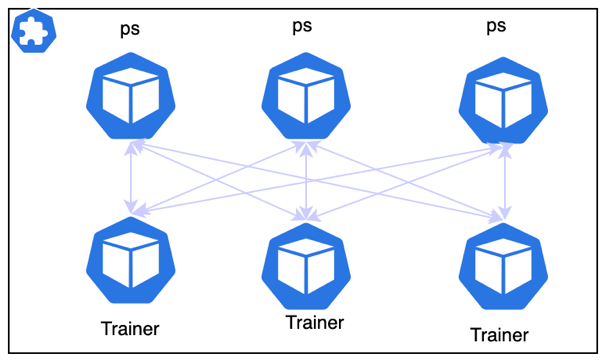
在Globlinlab平台上通过K8S TF-Operator,实现训练任务的编排,通过TF-Operator,来构建ps架构的分布式训练任务;需要解决paddle和tensorflow之间在参数服务器Role命名不同的问题,我们实现中间层,使paddle分布式训练任务可以完美适配TF_CONFIG:

3.4 弹性扩容
前面我们提到,云音乐数据的规模非常大,导致在GraphService 加载子图,以及tfjobs进行模型训练的时候,需要大量计算资源;为此,我们采用了基于k8s virtual-kubelet弹性资源扩容方案;
Virtual Kubelet是Kubernetes kubelet的一个实现,能把任何外部可容器化部署的计算资源进行统一封装,然后以 k8s node的形式注册到资源使用方的k8s集群中。
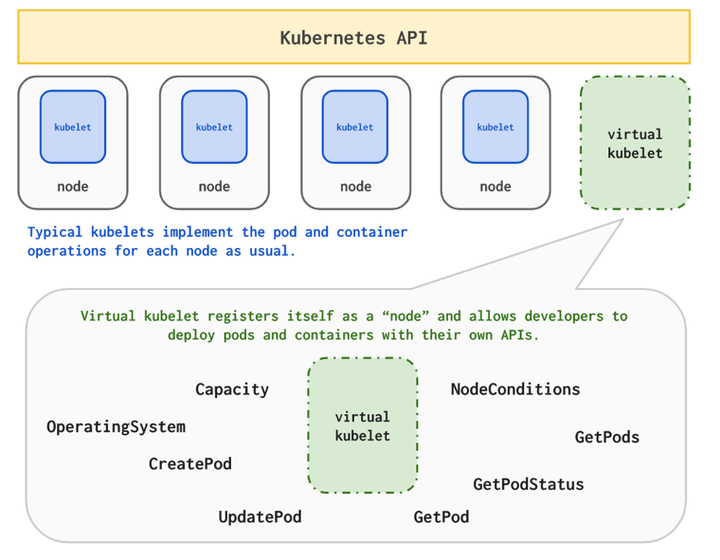
该方案优点:
聚合各种Provider集群碎片资源灵活的资源共享策略普适性好,部署简单标准化接口通过该方案,我们将GraphService和分布式训练任务编排到具有冗余计算资源的外部集群,目前可以提供1300核CPU,正扩容到3600核(可省约200多万/年)。 算力充足后可多任务并行,训练模型迭代更快;
3.5 分布式共享存储
数据加载,模型、日志存储离不开存储资源,Goblinlab平台提供Cephfs 分布式共享存储,来满足在多任务并行样本数据下载,模型并行保存;日志并行保存等功能;
Cephfs 文件系统特点:
提供弹性存储,支持动态扩缩容、数据安全、高性能、提升资源利用率(混部);简化数据治理,支持多读多写:并行下载(多写),分布式采样(多读)、日志收集等简化调度系统,支持多挂载,调度系统无需考虑数据位置共享存储会占用大量网络带宽; 模型训练中PS和Trainer之间也需要实时的网络通信;为防止IO网络和计算网络相互影响,我们采用了实现了计算存储分离架构:
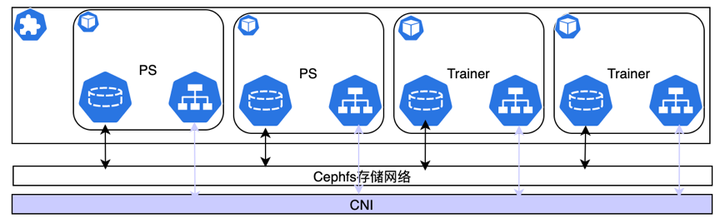
简单来说,就是PS和Trainer之间的通信和网络存储使用不同的网卡,两者从物理上隔离,不会相互影响;
3.6 框架封装
为方便后续平台化与业务交付, 我们将大规模图神经网络罗框架进行基础的封装,保证用户仅需要开发少量的模型代码,即可完成大规模分布式的图神经网络的开发,封装主要包括以下几个方面:
数据格式标准化:网易云音乐依托出站业务,衍生出多种创新业务;业务多样性带来数据的多样性;因此要实现一个通用图数据开发框架,首先应该制定标准的数据格式;我们在对接了多个业务部门的数据后,制定了可以适用多个各种场景、支持各种图结构的数据标准, 我们基于标准数据格式,实现了数据采样、模型开发的抽象统一;数据接口标准化, 除了数据格式的统一,还要基于这个标准实现抽象统一的数据接口:统一的数据采样流程:有了标准的数据格式,就可以对数据采样流程进行抽象统一,业务方只需专注于样本如何使用,而不用重复复杂的数据io开发;我们将数据采样流程抽象为两个标准接口:节点采样接口:支持随机节点采样、基于节点类型采样;样本采样接口:以节点采样结果作为起始节点在图上进行游走采样,既支持随机游走采样、基于metapath的随机游走采样;还支持子图采样;异步IO:数据采样效率限制模型训练时间,我们通过异步IO进一步优化数据采样流程,加速模型产出;在实践中,该采样流程都能满足各个场景数据采样需求;模型开发框架:为达到最好的模型效果,用户需要不断进行模型开发、迭代;因此我们抽象出标准的模型开发框架,对接标准的数据格式及统一的采样流程,业务方只需要开发前向计算逻辑即可;同时支持多种开箱即用的模型:deepwalk,metapath2vec、graphSage、NGCF、lightGCN,对于这些模型,用户只需要提供数据,即可在goblin平台进行训练;分布式训练封装:不同业务数据规模有大有小,业务方在模型开发阶段,仅需小数据单机训练,进行快速模型迭代,当模型实际使用时,则面对的是超大规模的数据,单机无法训练;为此我们进行了分布式训练封装,框架根据用户在启动任务时,选择的副本数,自动执行单机或分布式训练;GPU加速:有些创新业务,数据规模较小,可以进行单机训练;而动辄数小时的训练时长,严重影响模型开发效率;为加速单机模型的训练速度,我们支持GPU加速,将数小时训练优化到分钟级别,加快业务落地;模型实践
除了在工程上,不断对技术栈进行优化;我们也一直跟进业务方需求,不断提供符合业务方需求的模型;本章详细介绍模型方面的实践;
DeepWalk
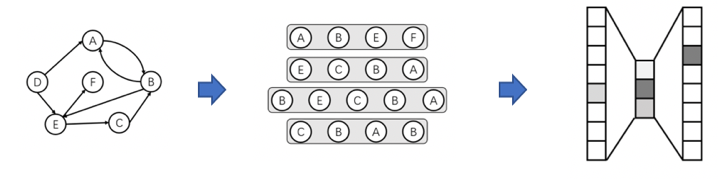
在KDD2014中提出的算法,借鉴了word2vec算法的思想,通过使用随机游走(RandomWalk)的方式在图中进行节点采样来模拟语料库中的预料,从而得到图中节点与节点的共现关系来学习节点的向量表示。
场景:云音乐直播推荐业务
云音乐用户在主播相关的行为较少充分利用用户在其他资源(歌曲,mlog,dj)上的行为,将这些用户行为学习到的用户风格用于指导主播召回,排序等模型,提高主播业务渗透率ctr与ctcvr在这两路召回中与similarity均呈现较大正相关性Metapath2vec
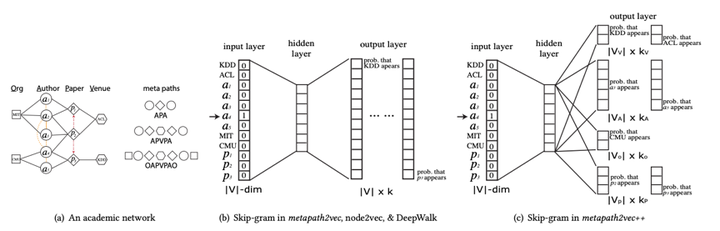
发表于kdd2017,专门用于异构网络表征学习的方法。使用基于元路径的随机游走方法来捕捉节点的异构邻居,然后使用异构 Skip-Gram 模型进行训练,同时建模结构上和语义上相近的节点。
场景:用户隐性关系链
使用全站的用户行为数据(音乐、搜索、云村、播客等),构建用户的隐向量表征,刻画用户之间的隐性关系
效果Case:
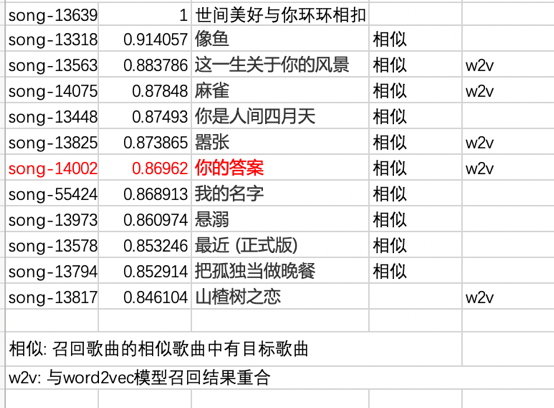
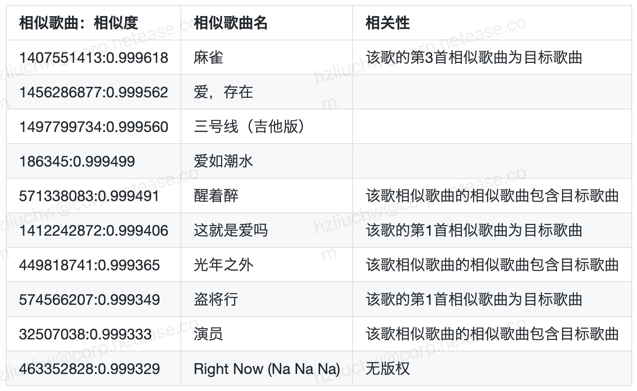
我们采用i2i验证方式,分别选取 <<世间美好与你环环相扣>> 、《起风了》 作为目标歌曲,通过faiss-tool,召回与其相近的top 10歌曲; 两首歌是否相似有一定主观性,所以我们会根据传统协同过滤结果,来佐证歌曲之间的相关性;
目标歌曲:《世间美好与你环环相扣》
传统协同过滤相似歌曲列表
模型召回离线召回歌曲列表:
NGCF
在用户隐性关系链场景中,我们通过用户红心歌曲数据,构建了user 和 song的二部图,并在数百亿边的数据规模下,实现基于metapath的random walk 模型训练;为进一步提升图计算模型效果,我们尝试在同样数据规模下实现NGCF模型,并对模型效果进行验证;超大规模场景实现GCN网络NGCF通过GCN建模User-Item 之间的高阶连接性,PGL采用消息传递范式实现GCN网络,目前在超大规模图上还无法构建GCN网络。基于自封装的easygraph框架,将所有采样出来的节点在本地构建user-item 二部图,通过本地二部图实现message passing;
模型召回效果:
LightGCN
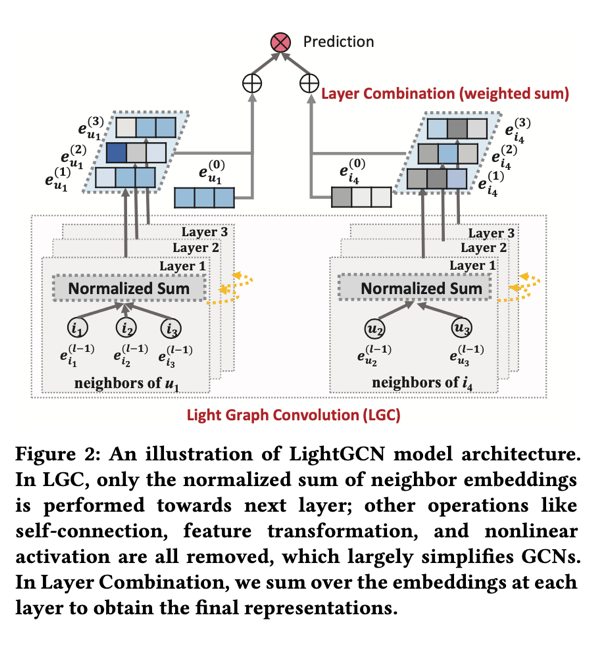
SIGIR2020 针对基于GCN进行CF的算法研究。作者通过实验发现GCN中的特征转换和非线性激活对于CF的效果作用不大,甚至可能影响推荐效果,作者提出了LightGCN模型;LightGCN简化GCN, 只包含最基本的结构(邻居聚合)用于协同过滤。这种简单、线性的模型是很容易实施和训练的,并且在同样的实验条件下相对于NGCF有了实质性的改善(相对平均提升了16.0%)。
网络架构:
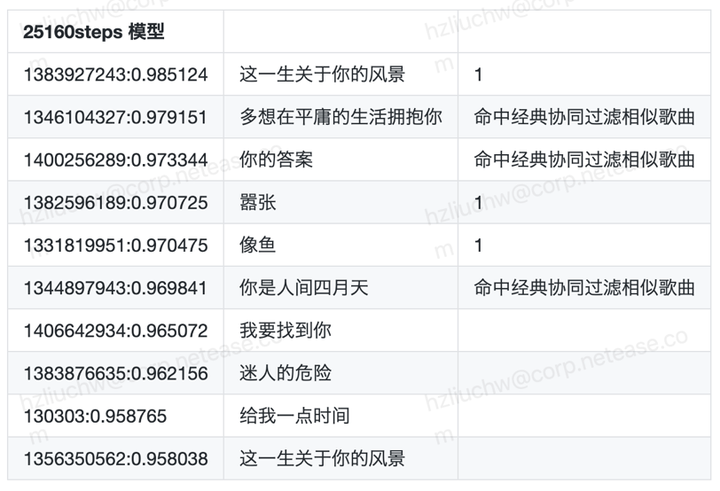
召回效果:
总结与后续规划:
以上是我们目前在超大规模图计算方面的一些实践总结,该方案在业务时间中取得了一定的效果,但也存在一些问题:
离线验证还是比较主观,针对于节点表征这类问题,目前暂没有很好的评估方式,常见的评估方式包括使用相关表征向量落地线上业务,但是由于路径太长,评估存在不客观的情况;离线召回的向量集以及召回速度还有待优化,尤其是针对于巨图,保证所有节点离线召回满足准确率与性能的需求,还需要更多的实验尝试,目前已有部分工作,后续会统一整理;模型种类还有待丰富,目前学术界关于图神经网络研究较多,如何选择合适的网络结构,支持落地在工业界场景,目前仍有很大的挑战;综合考虑成本因素,未实验更大数据量计算,后续在VK资源满足需求后,实验千亿乃至万亿边的图网络;图计算的上述工作离不开各个团队的支持。首先,感谢各个业务组在图神经网络推进中给予的支持和肯定尤其是隐性关系链共建中的各位同学,帮助我们将图神经网络推向业务落地,感谢杭研云计算在VK计算资源中给予的帮助,也感谢百度飞桨社区和PGL相关同学在框架侧给予的支持,最后感谢磊哥、飞哥、川江、官林等各位老板在整个项目中的指导与支持。
